Gemini 3 Pro Image (Nano Banana 2) 完整教學:功能差異、Prompt 技巧與各領域應用全解析

2025年11月21日 上午 2:51
AI 相關知識2025 年 11 月,Google DeepMind 正式發布了 Gemini 3.0 模型家族,其中最受創意與開發社群矚目的,莫過於其圖像生成模組,官方名稱為 Gemini 3 Pro Image,但在社群與早期測試者口中,它擁有一個更為親切且具病毒傳播力的代號:「Nano Banana 2」或「Nano Banana Pro」。
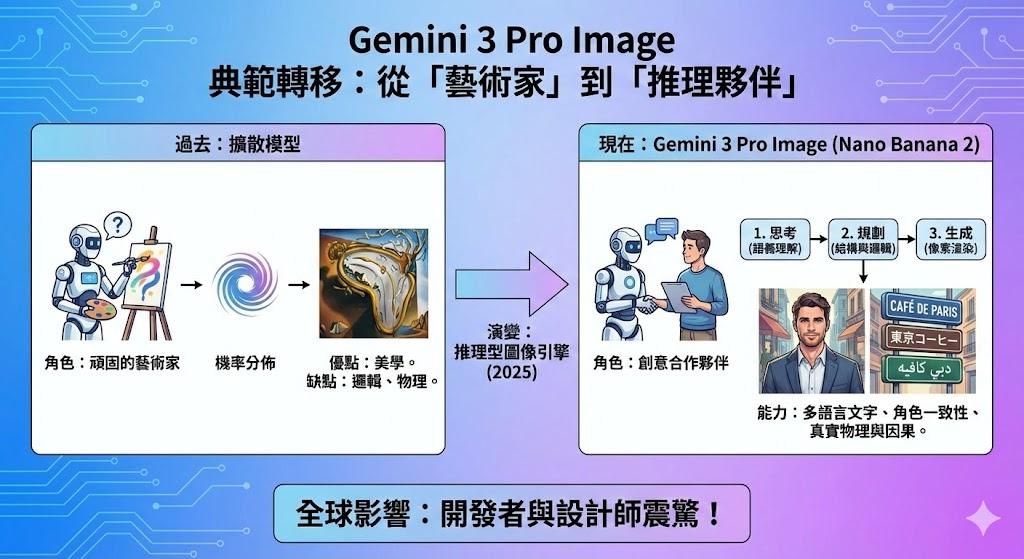
這一代模型的問世,標誌著圖像生成技術的一次根本性典範轉移:從單純依賴機率分佈的擴散模型(Diffusion Models),進化為具備深度語義理解與邏輯規劃能力的「推理型圖像引擎」(Reasoning Image Engine)。
過去的圖像生成模型,如 Midjourney 或早期的 Stable Diffusion,主要扮演「頑固的藝術家」角色,它們擅長創造美學上令人驚豔的視覺效果,但在遵循複雜指令、處理文字邏輯或維持物理一致性上往往力有未逮。Gemini 3 Pro Image 的出現打破了這一局限。它被設計為一個「創意合作夥伴」,利用 Gemini 3.0 語言模型強大的推理核心,在生成像素之前先「思考」場景結構、因果關係與光影邏輯。這種架構上的革新,使得該模型在處理多語言文字渲染、複雜的角色一致性以及基於真實世界知識的圖像生成上,展現了前所未有的能力,引發了全球開發者與設計師的震驚與熱烈討論。
「Nano Banana」現象:品牌與社群的共鳴
「Nano Banana」這個名稱最初僅是 Google 內部的開發代號,用於指代 Gemini 2.5 Flash Image 模型。然而,由於該模型在 2025 年 8 月的早期測試中展現了驚人的生成速度與生成「超寫實微縮模型」(Hyper-realistic Figurines)的能力,這個帶有戲謔意味的名稱迅速在 Reddit 與 Twitter(現 X)等社群平台上爆紅。
當 Google 隨後推出更強大的 Gemini 3 Pro Image 時,社群自然地將其延續稱為「Nano Banana 2」或「Nano Banana Pro」。這種非官方名稱的流行,反映了 AI 社群對於一款既具備強大企業級功能,又擁有親民、易於實驗特性的工具的渴望。儘管 Google 官方正式定名為 Gemini 3 Pro Image,但在本報告中,我們將同時使用這兩個名稱,以反映技術規範與社群文化的雙重脈絡。

架構解析:推理驅動的視覺合成引擎
Gemini 3 Pro Image 之所以能產生「震驚」效果,並非單純依靠增加參數或訓練數據,而是在底層架構上引入了「思考」與「規劃」的維度。
「思考模式」與中介推理
傳統的文生圖模型通常是將提示詞直接映射為視覺特徵向量,然後透過去噪過程生成圖像。這種直連方式容易導致「幻覺」或邏輯謬誤(例如:要求「沒有香腸的披薩」卻生成了香腸,因為模型只捕捉到了「香腸」這個關鍵詞)。
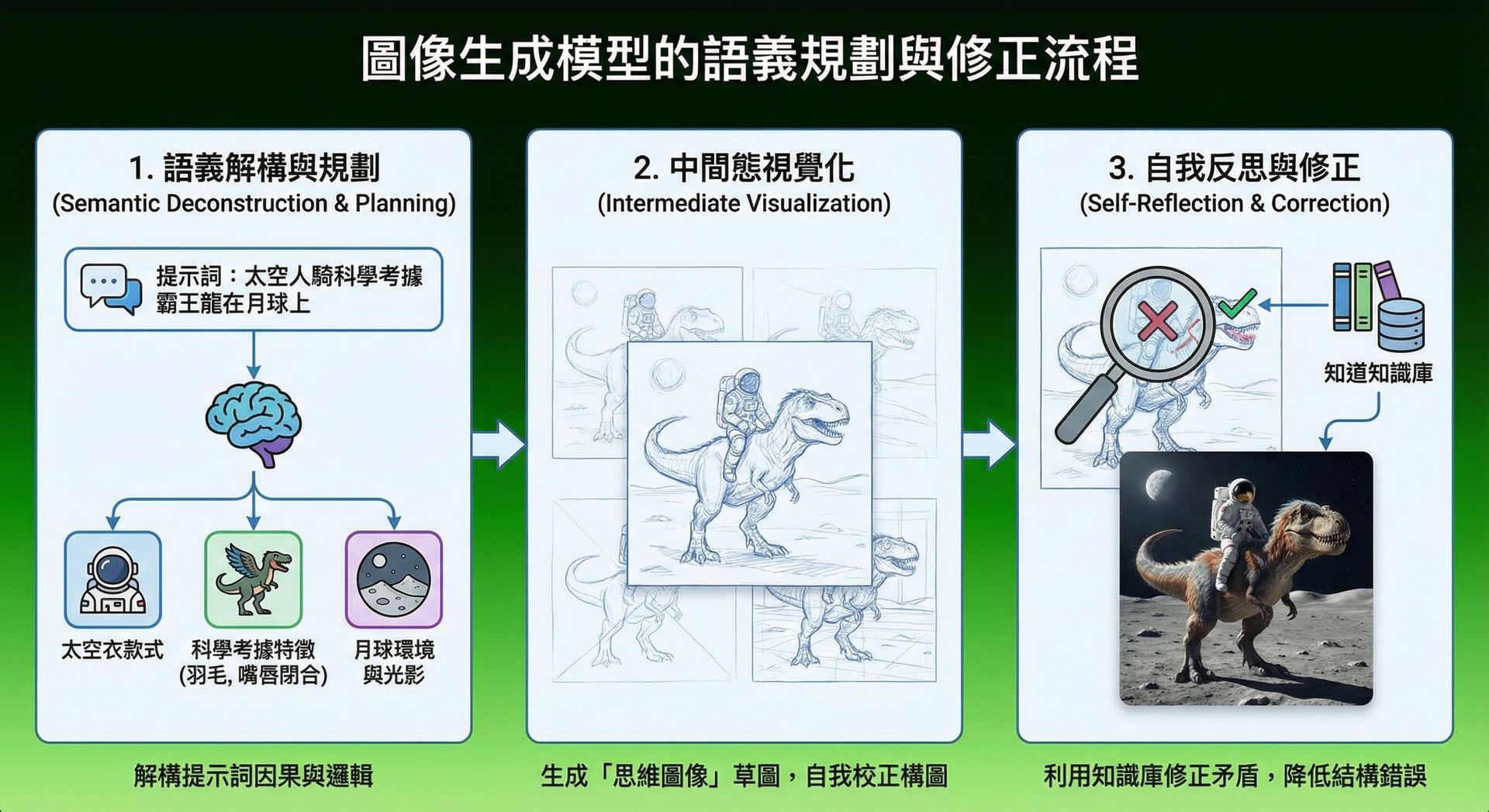
Gemini 3 Pro Image 引入了源自 Gemini 3.0 LLM 的「思考模式」。當用戶啟用此模式時,模型不會立即生成圖像,而是先進行多步驟的邏輯推理:
- 語義解構與規劃:模型首先分析提示詞中的因果關係與空間邏輯。例如,面對「一個太空人騎著一隻符合科學考據的霸王龍在月球上」這樣的複雜指令,模型會先規劃:太空人穿什麼太空衣?霸王龍的科學考據特徵是什麼(有羽毛、嘴唇閉合)?月球的光影該如何呈現?
- 中間態視覺化:在後端,模型會生成一系列「思維圖像」或結構草圖,用於自我校正構圖與邏輯,雖然用戶看不到這些中間產物,但它們確保了最終輸出的邏輯連貫性。
- 自我反思與修正:如果模型發現初步規劃中存在矛盾(例如霸王龍的解剖結構錯誤),它會利用內部的知識庫進行修正,這顯著降低了傳統模型常見的「恐怖谷」效應或結構錯誤。

多模態視覺上下文視窗
Gemini 3 Pro Image 的另一個核心突破在於其巨大的「視覺上下文視窗」。傳統模型通常只能接受單張或極少量的參考圖,且往往容易丟失參考圖的特徵。
Gemini 3 Pro Image 支援同時輸入多達 14 張參考圖像。這意味著設計師可以一次性上傳:
- 品牌識別規範(Logo、色票)
- 產品三視圖(正面、側面、細節)
- 角色設計圖
- 光影參考圖
模型能夠將這些離散的視覺資訊進行語義融合,在生成的新圖像中同時保持所有參考素材的特徵。這實際上是在視覺領域實現了「少樣本學習」,讓模型在不需要重新訓練的情況下,就能精準掌握特定的藝術風格或品牌調性。
技術規格與解析度躍升
從「Nano Banana」(Gemini 2.5 Flash)到「Nano Banana Pro」(Gemini 3 Pro Image),技術規格經歷了顯著的升級:
技術指標 | Gemini 2.5 Flash Image | Gemini 3 Pro Image | 技術優勢分析 |
最大解析度 | 約 1024 x 1024 (1 MP) | 原生支援 1K, 2K, 甚至 4K | 4K 解析度使得生成的圖像可直接用於印刷、大型廣告看板,無需依賴第三方放大工具 。 |
參考圖像數量 | 單張或少量 | 最多 14 張 | 極大提升了複雜場景合成與風格遷移的可控性 。 |
文字渲染能力 | 基礎,常有亂碼 | 高保真,多語言支援 | 解決了 AI 生成圖像中文字不可讀的痛點,支援長段落與圖表標籤 。 |
推理能力 | 直覺式生成 | 具備「思考」模式 | 能夠處理複雜邏輯指令(如「先做A,再做B」)與事實查核 。 |
真實世界接地 | 有限 | 整合 Google Search | 可生成反映即時數據(如天氣、股市)或歷史準確性的圖像 。 |
核心功能與「震驚」社群的突破點
社群對於 Gemini 3 Pro Image 的震驚反應,主要集中在它解決了生成式 AI 長久以來的幾個「阿基里斯之踵」。
解決「排版悖論」:高保真多語言文字渲染
長久以來,AI 繪圖模型在處理文字時總是力不從心,生成的文字往往是無意義的符號。Gemini 3 Pro Image 利用 Gemini 3.0 強大的語言理解能力,將文字視為圖像中的「一等公民」。
- 資訊圖表生成:這一代模型最強大的應用之一是能夠生成「資訊圖表」。用戶只需輸入「製作一張關於如何製作印度香料奶茶的流程圖」,模型便能自行搜尋食譜,規劃步驟,並生成一張包含準確插圖與清晰文字說明的圖表。這種將抽象知識轉化為結構化視覺資訊的能力,是純擴散模型無法企及的。
- 多語言支援:它不僅能生成英文,還能準確渲染繁體中文等複雜文字系統。例如,在社群中廣為流傳的案例是,用戶要求模型將畫面中汽水罐上的英文標籤翻譯成中文,模型不僅完成了翻譯,還完美保留了原本的包裝設計風格與光影質感。


角色與物件的一致性
對於漫畫家、品牌行銷人員而言,AI 最大的痛點是「角色長相不連貫」。Gemini 3 Pro Image 透過「參考種子」與強大的語義鎖定技術,解決了這個問題。
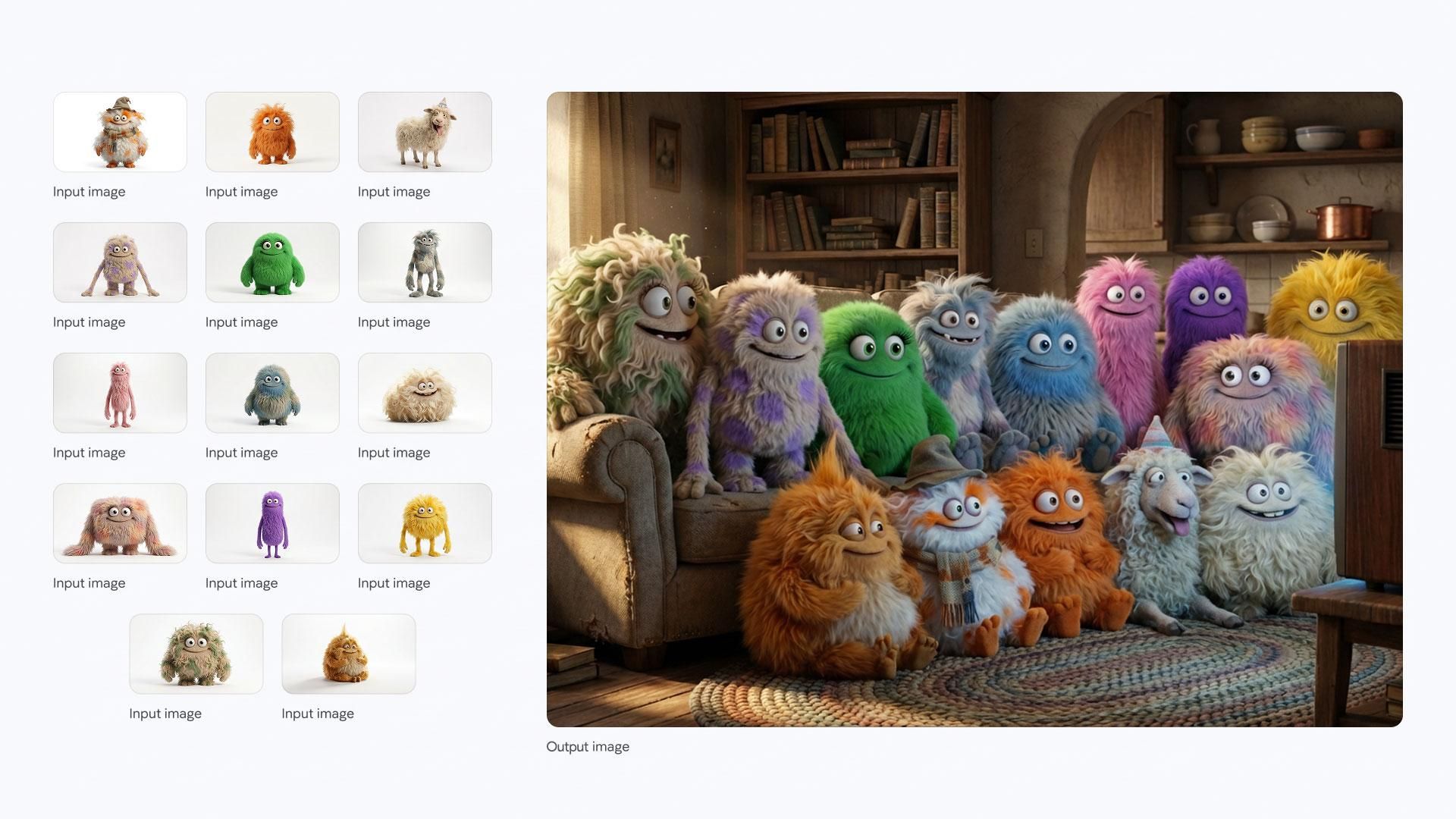
多角色融合:模型可以同時維持多達 5 個不同角色的面部特徵一致性。在一個測試案例中,用戶輸入了 14 張不同絨毛玩具的照片,模型成功將它們合成在一張客廳看電視的圖像中,每隻玩具的特徵都得到了保留,沒有發生混淆或變形。
各領域高手的應用方式與工作流解析
隨著 Gemini 3 Pro Image 的發布,網路上的高手與專業用戶迅速開發出了多種針對不同領域的高階應用方式。以下是針對主要領域的深度解析。
電子商務:虛擬攝影棚與產品在地化
痛點:傳統電商需要為每件商品拍攝大量情境照,且若需更換模特兒或背景,成本極高。
Nano Banana Pro 解決方案:
- 虛擬穿戴與模特兒置換:利用模型的 14 圖輸入能力,商家可以上傳一張「平鋪的服裝照」和一張「模特兒照片」。
- 提示詞範例:「將圖像 A 中的連衣裙穿在圖像 B 的模特兒身上。保持布料的絲綢質感與自然垂墜感,調整光影以符合模特兒所處的室外自然光環境。」
- 效果:模型能理解衣物的物理材質(如絲綢的反光),並將其自然地合成到模特兒身上,省去了實體拍攝的繁瑣。
- 產品背景重構:將白底產品照轉化為生活情境照。
- 提示詞範例:「將這張霧面黑色保溫瓶(圖像 1)放置在清晨佈滿露水的混凝土表面上。添加從左側射入的柔和藍色邊緣光,背景為模糊的城市公園。」
- 進階技巧:利用「思考模式」進行對話式微調。如果倒影不夠真實,可以追問:「增加混凝土表面的潮濕感,讓保溫瓶的倒影更清晰。」
- 全球行銷素材在地化:針對跨國品牌,同一張產品宣傳圖需要適配不同語言。
- 工作流:生成一張包含產品包裝的主視覺圖。接著使用指令:「將包裝上的英文『Energy』替換為日文『元気』,保持原有的字體設計風格與金屬質感。」模型會執行紋理感知的文字替換,而非簡單的覆蓋。
品牌行銷與廣告:一致性與創意迭代
痛點:AI 生成的圖像往往風格跳躍,難以維持品牌識別系統的一致性。
Nano Banana Pro 解決方案:
品牌風格鎖定:行銷人員可以上傳品牌的 Logo、標準色票、以及過去成功的廣告圖作為參考。
提示詞範例:「根據參考圖像 A 的配色方案與參考圖像 B 的構圖風格,為我們的新產品(圖像 C)生成一系列 Instagram 廣告圖。確保 Logo(圖像 D)以自然的 3D 浮雕效果出現在背景牆面上。」
優勢:這相當於為 AI 戴上了「品牌濾鏡」,確保生成的所有素材都符合品牌調性。
遊戲開發與概念設計:資產重製與概念驗證
痛點:概念美術與 3D 資產之間的轉換往往需要大量人力。
Nano Banana Pro 解決方案:
- 低模資產重製:開發者可以將遊戲中的粗糙 3D 模型截圖上傳。
- 提示詞範例:「將這個低多邊形的汽車模型重製為照片級真實的跑車。增加金屬漆面細節,保留原本的透視角度,背景改為賽博龐克風格的街道。」
- 效果:模型能「腦補」出缺失的細節,快速將草圖轉化為高完成度的宣傳圖。
- 風格遷移與材質生成:利用模型對材質的理解,生成無縫貼圖。
- 提示詞:「生成一張 4K 解析度的舊化外星金屬表面紋理,帶有綠色氧化痕跡與微小的發光電路細節。」這些生成的圖像可以直接作為 3D 模型的貼圖素材。


教育與學術研究:視覺化複雜知識
痛點:製作準確的科學插圖或教學圖表通常需要專業插畫家。
Nano Banana Pro 解決方案:
- 知識視覺化:這是 Gemini 3 Pro Image 最具差異化的功能。
- 案例:「生成一張解釋敏捷開發四大支柱的現代風格資訊圖表。支柱 1:個人與互動...(以此類推)。使用簡潔的圖標與線性流程佈局。」
- 病毒式應用:社群中有人利用此功能將手寫的筆記照片上傳,要求模型:「將這張手寫的物理筆記轉化為一張清晰、出版級的科學圖表。」模型不僅辨識了潦草的字跡,還重繪了標準的物理示意圖。
高階提示工程(Prompt Engineering)指南
為了駕馭 Gemini 3 Pro Image 的強大能力,Google 官方與社群高手總結出了「七大核心提示技巧」與結構化提示方法。
結構化提示詞公式
一個專業的 Nano Banana Pro 提示詞應包含以下五個要素:
- 主體:明確的人或物(例如:「一個堅毅的機器人咖啡師,眼睛發出藍光」)。
- 構圖:鏡頭語言(例如:「低角度仰拍,廣角鏡頭,f/1.8 大光圈」)。
- 動作:正在發生什麼(例如:「正在將牛奶倒入咖啡杯中,液體呈現動態飛濺」)。
- 環境:詳細的背景描述(例如:「火星上的未來主義咖啡館,窗外有紅色沙塵暴」)。
- 風格:美學規範(例如:「3D 渲染風格,Pixar 動畫質感,或 1990 年代產品攝影風格」)。
七大核心應用技巧
- 極致的文字渲染:在提示詞中明確指定文字內容與樣式。
- 範例:「海報標題為『SPACE』,使用粗體無襯線字體,白色,位於頂部。」
- 真實世界接地:利用 Google Search 確保內容準確。
- 範例:「繪製一張科學準確的 CSTR 反應器剖面圖。」
- 翻譯與在地化:利用圖像到圖像功能進行文字替換。
- 範例:「將圖中所有的英文路標翻譯成法文,保持路標的金屬舊化質感。」
- 攝影棚級控制:像導演一樣控制光影。
- 範例:「將場景改為夜間,光源改為霓虹燈管的冷色調。」
- 精確尺寸調整:針對不同平台輸出。
- 範例:「將這張 1:1 的圖像擴展為 16:9 的電影畫面,填補兩側的背景細節。」
- 多圖混合與角色一致性:使用 14 圖輸入槽。
- 範例:「結合這些參考圖,生成一張全家福,保持每個人物的面部特徵。」
- 品牌識別維護:上傳 VIS 規範。
- 範例:「將此 Logo 應用於 T 恤上,模擬布料的褶皺與光影。」
競品分析:Gemini 3 Pro Image vs. Midjourney vs. DALL-E 3
在目前的 AI 圖像生成戰場上,主要形成了「實用主義」與「藝術主義」兩大陣營。
比較維度 | Gemini 3 Pro Image (Nano Banana Pro) | Midjourney | DALL-E 3 (ChatGPT) |
定位 | 全能創意夥伴 / 企業級工具 | 頑固的藝術家 | 大眾化圖文助手 |
文字渲染 | 卓越:支援多語言、長段落、複雜排版,準確率極高 30。 | 普通:版本有進步,但仍常有拼寫錯誤,不適合長文。 | 良好:能處理簡單對話與標題,但易有錯字。 |
寫實度 | 極高:偏向「攝影紀實」風格,物理光影準確 31。 | 頂級:偏向「電影美學」與「藝術感」,光影具戲劇性。 | 中等:常有一種明顯的「AI 塑膠感」或過度飽和。 |
指令遵循度 | 極高:推理引擎確保邏輯嚴密(如數量、位置關係)。 | 中等:為了美學往往會忽略部分複雜指令。 | 高:透過 ChatGPT 的語言理解,能很好地遵循指令。 |
工作流整合 | 深度整合:Vertex AI, Google Workspace, Android 系統。 | 封閉:主要依賴 Discord 或專屬 Web,難以自動化。 | 整合:整合於 ChatGPT 與 Microsoft Designer。 |
參考圖輸入 | 14 張:強大的合成與風格鎖定能力 11。 | 有限:支援 Image Prompt,但控制力不如 Gemini 精細。 | 有限:主要依賴文字描述。 |
適用場景 | 電商、行銷素材、資訊圖表、複雜邏輯場景。 | 藝術創作、概念美術、氛圍圖(Mood Board)。 | 快速配圖、迷因製作、簡單插畫。 |
技術實作與存取
目前開發者與企業用戶可以透過以下管道存取 Gemini 3 Pro Image:
Google AI Studio:適合開發者進行原型設計與測試。
Gemini App (Advanced/Ultra):適合個人創作者與專業用戶,提供直觀的對話式介面。
Vertex AI:適合企業級部署,提供 API 接入與數據隱私保障。
開發者工具:Antigravity 與 CLI
Google 同步推出了 Google Antigravity 平台與 Gemini CLI 工具。
- Gemini CLI:允許開發者在終端機直接調用模型,進行批次圖像處理或自動化腳本編寫。
- Antigravity:這是一個新的代理開發平台,開發者可以構建能夠自主使用 Gemini 3 Pro Image 的 AI 代理,例如「自動為每一篇新發布的部落格文章生成配圖」的自動化機器人。
安全與浮水印
所有由 Gemini 3 Pro Image 生成的圖像均內嵌了 SynthID 數位浮水印。這是一種人眼不可見,但可被專用軟體檢測的技術,旨在防止 Deepfakes 的濫用並標註 AI 生成內容的來源,這對於企業用戶來說是合規性的重要保障。


結論
Gemini 3 Pro Image(Nano Banana 2)的發布,不僅僅是解析度的提升,更是 AI 從「直覺生成」邁向「邏輯推理」的里程碑。它證明了當強大的語言模型與圖像生成模型深度結合時,能夠解決過去被認為是 AI 「硬傷」的文字渲染、空間邏輯與角色一致性問題。
對於創意工作者而言,這意味著 AI 不再是一個需要不斷「抽卡」碰運氣的玩具,而是一個可控、可預期且能融入專業工作流的生產力工具。隨著未來 Veo(影片生成模型)與 3D 功能的進一步整合,我們預見 Gemini 生態系將徹底改變數位內容生產的格局,讓從靜態圖像到動態影音的創作邊界變得更加模糊且自由。